File
A file is a named collection of related information that is recorded on secondary storage such as magnetic disks, magnetic tapes and optical disks. In general, a file is a sequence of bits, bytes, lines or records whose meaning is defined by the files creator and user.
File Structure
A File Structure should be according to a required format that the operating system can understand.
- A file has a certain defined structure according to its type.
- A text file is a sequence of characters organized into lines.
- A source file is a sequence of procedures and functions.
- An object file is a sequence of bytes organized into blocks that are understandable by the machine.
- When operating system defines different file structures, it also contains the code to support these file structure. Unix, MS-DOS support minimum number of file structure.
File Type
File type refers to the ability of the operating system to distinguish different types of file such as text files source files and binary files etc. Many operating systems support many types of files. Operating system like MS-DOS and UNIX have the following types of files −
Ordinary files
- These are the files that contain user information.
- These may have text, databases or executable program.
- The user can apply various operations on such files like add, modify, delete or even remove the entire file.
Directory files
- These files contain list of file names and other information related to these files.
Special files
- These files are also known as device files.
- These files represent physical device like disks, terminals, printers, networks, tape drive etc.
These files are of two types −
- Character special files − data is handled character by character as in case of terminals or printers.
- Block special files − data is handled in blocks as in the case of disks and tapes.
File Access Mechanisms
File access mechanism refers to the manner in which the records of a file may be accessed. There are several ways to access files −
- Sequential access
- Direct/Random access
- Indexed sequential access
Sequential access
A sequential access is that in which the records are accessed in some sequence, i.e., the information in the file is processed in order, one record after the other. This access method is the most primitive one. Example: Compilers usually access files in this fashion.
Direct/Random access
- Random access file organization provides, accessing the records directly.
- Each record has its own address on the file with by the help of which it can be directly accessed for reading or writing.
- The records need not be in any sequence within the file and they need not be in adjacent locations on the storage medium.
Indexed sequential access
- This mechanism is built up on base of sequential access.
- An index is created for each file which contains pointers to various blocks.
- Index is searched sequentially and its pointer is used to access the file directly.
Space Allocation
Files are allocated disk spaces by operating system. Operating systems deploy following three main ways to allocate disk space to files.
- Contiguous Allocation
- Linked Allocation
- Indexed Allocation
Contiguous Allocation
- Each file occupies a contiguous address space on disk.
- Assigned disk address is in linear order.
- Easy to implement.
- External fragmentation is a major issue with this type of allocation technique.
Linked Allocation
- Each file carries a list of links to disk blocks.
- Directory contains link / pointer to first block of a file.
- No external fragmentation
- Effectively used in sequential access file.
- Inefficient in case of direct access file.
Indexed Allocation
- Provides solutions to problems of contiguous and linked allocation.
- A index block is created having all pointers to files.
- Each file has its own index block which stores the addresses of disk space occupied by the file.
- Directory contains the addresses of index blocks of files.
SFS (Symbolic File System)
A command line utility that provides a lightweight setup for organizing and backing up files
SFS stores files from a variety of sources, aka collections, that may include directories and removable media, as symbolic links to the source files. It also stores the metadata of the source files so that files can later be queried without having to plug in the source media.
An SFS is a managed directory which is initialized with the command: sfs init. All commands to be executed in the context of an individual SFS must be run from within the SFS directory tree. Files are added using the command sfs add-col my_collection /path/to/source (add collection). SFS Files are symlinks to source files in added collections. Foreign links and other files can also exist in an SFS but they are not managed by it and are mostly ignored.
Physical files contain the actual data that is stored on the system, and a description of how data is to be presented to or received from a program. They contain only one record format, and one or more members. Records in database files can be externally or program-described.
A physical file can have a keyed sequence access path. This means that data is presented to a program in a sequence based on one or more key fields in the file.
Logical files do not contain data. They contain a description of records found in one or more physical files. A logical file is a view or representation of one or more physical files. Logical files that contain more than one format are referred to as multi-format logical files.
If your program processes a logical file which contains more than one record format, you can use a read by record format to set the format you wish to use.
FILE DIRECTORIES:
Collection of files is a file directory. The directory contains information about the files, including attributes, location and ownership. Much of this information, especially that is concerned with storage, is managed by the operating system. The directory is itself a file, accessible by various file management routines.
Information contained in a device directory are:
- Name
- Type
- Address
- Current length
- Maximum length
- Date last accessed
- Date last updated
- Owner id
- Protection information
Operation performed on directory are:
- Search for a file
- Create a file
- Delete a file
- List a directory
- Rename a file
- Traverse the file system
Advantages of maintaining directories are:
- Efficiency: A file can be located more quickly.
- Naming: It becomes convenient for users as two users can have same name for different files or may have different name for same file.
- Grouping: Logical grouping of files can be done by properties e.g. all java programs, all games etc.
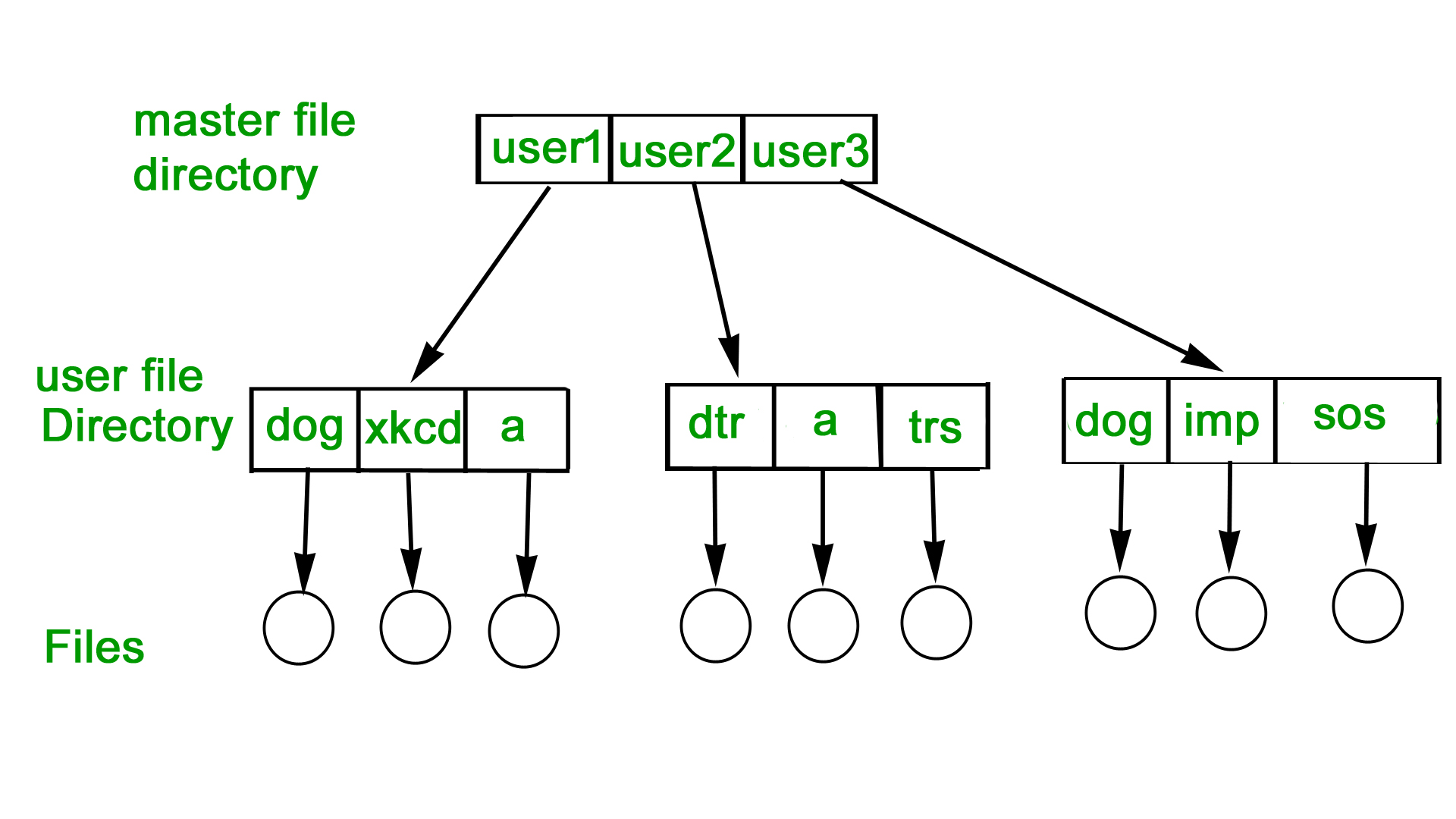
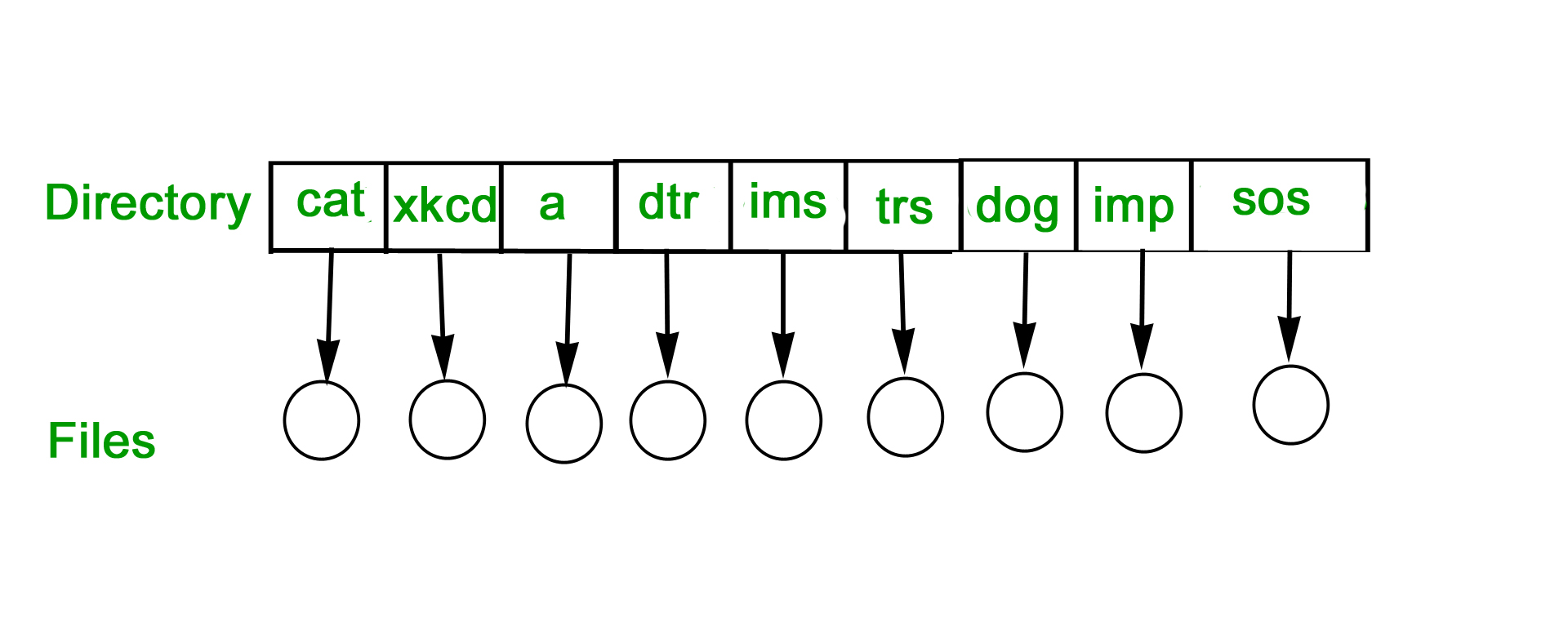
SINGLE-LEVEL DIRECTORY
In this a single directory is maintained for all the users.
- Naming problem: Users cannot have same name for two files.
- Grouping problem: Users cannot group files according to their need.

TWO-LEVEL DIRECTORY
In this separate directories for each user is maintained.
- Path name:Due to two levels there is a path name for every file to locate that file.
- Now,we can have same file name for different user.
- Searching is efficient in this method.


FILE ALLOCATION METHODS
1. Continuous Allocation: A single continuous set of blocks is allocated to a file at the time of file creation. Thus, this is a pre-allocation strategy, using variable size portions. The file allocation table needs just a single entry for each file, showing the starting block and the length of the file. This method is best from the point of view of the individual sequential file. Multiple blocks can be read in at a time to improve I/O performance for sequential processing. It is also easy to retrieve a single block. For example, if a file starts at block b, and the ith block of the file is wanted, its location on secondary storage is simply b+i-1.

Disadvantage
- External fragmentation will occur, making it difficult to find contiguous blocks of space of sufficient length. Compaction algorithm will be necessary to free up additional space on disk.
- Also, with pre-allocation, it is necessary to declare the size of the file at the time of creation.
2. Linked Allocation(Non-contiguous allocation) : Allocation is on an individual block basis. Each block contains a pointer to the next block in the chain. Again the file table needs just a single entry for each file, showing the starting block and the length of the file. Although pre-allocation is possible, it is more common simply to allocate blocks as needed. Any free block can be added to the chain. The blocks need not be continuous. Increase in file size is always possible if free disk block is available. There is no external fragmentation because only one block at a time is needed but there can be internal fragmentation but it exists only in the last disk block of file.
Disadvantage:
- Internal fragmentation exists in last disk block of file.
- There is an overhead of maintaining the pointer in every disk block.
- If the pointer of any disk block is lost, the file will be truncated.
- It supports only the sequencial access of files.

3. Indexed Allocation:
It addresses many of the problems of contiguous and chained allocation. In this case, the file allocation table contains a separate one-level index for each file: The index has one entry for each block allocated to the file. Allocation may be on the basis of fixed-size blocks or variable-sized blocks. Allocation by blocks eliminates external fragmentation, whereas allocation by variable-size blocks improves locality. This allocation technique supports both sequential and direct access to the file and thus is the most popular form of file allocation.
Disk Free Space Management
Just as the space that is allocated to files must be managed ,so the space that is not currently allocated to any file must be managed. To perform any of the file allocation techniques,it is necessary to know what blocks on the disk are available. Thus we need a disk allocation table in addition to a file allocation table.The following are the approaches used for free space management.
- Bit Tables : This method uses a vector containing one bit for each block on the disk. Each entry for a 0 corresponds to a free block and each 1 corresponds to a block in use.
For example: 00011010111100110001In this vector every bit correspond to a particular block and 0 implies that, that particular block is free and 1 implies that the block is already occupied. A bit table has the advantage that it is relatively easy to find one or a contiguous group of free blocks. Thus, a bit table works well with any of the file allocation methods. Another advantage is that it is as small as possible
- Free Block List : In this method, each block is assigned a number sequentially and the list of the numbers of all free blocks is maintained in a reserved block of the disk.

File Access Methods in Operating System
When a file is used, information is read and accessed into computer memory and there are several ways to access this information of the file. Some systems provide only one access method for files. Other systems, such as those of IBM, support many access methods, and choosing the right one for a particular application is a major design problem.
There are three ways to access a file into a computer system: Sequential-Access, Direct Access, Index sequential Method.
- Sequential Access –
It is the simplest access method. Information in the file is processed in order, one record after the other. This mode of access is by far the most common; for example, editor and compiler usually access the file in this fashion.
Read and write make up the bulk of the operation on a file. A read operation -read next- read the next position of the file and automatically advance a file pointer, which keeps track I/O location. Similarly, for the writewrite next append to the end of the file and advance to the newly written material.Key points:- Data is accessed one record right after another record in an order.
- When we use read command, it move ahead pointer by one
- When we use write command, it will allocate memory and move the pointer to the end of the file
- Such a method is reasonable for tape.
- Direct Access –
Another method is direct access method also known as relative access method. A filed-length logical record that allows the program to read and write record rapidly. in no particular order. The direct access is based on the disk model of a file since disk allows random access to any file block. For direct access, the file is viewed as a numbered sequence of block or record. Thus, we may read block 14 then block 59 and then we can write block 17. There is no restriction on the order of reading and writing for a direct access file.A block number provided by the user to the operating system is normally a relative block number, the first relative block of the file is 0 and then 1 and so on. - Index sequential method –
It is the other method of accessing a file which is built on the top of the direct access method. These methods construct an index for the file. The index, like an index in the back of a book, contains the pointer to the various blocks. To find a record in the file, we first search the index and then by the help of pointer we access the file directly.Key points:- It is built on top of Sequential access.
- It control the pointer by using index

{kind=link}
{kind=link}