What is Data
Data is nothing but facts and statistics stored or free flowing over a network, generally it’s raw and unprocessed. For example: When you visit any website, they might store you IP address, that is data, in return they might add a cookie in your browser, marking you that you visited the website, that is data, your name, it’s data, your age, it’s data.
Data becomes information when it is processed, turning it into something meaningful. Like, based on the cookie data saved on user’s browser, if a website can analyse that generally men of age 20-25 visit us more, that is information, derived from the data collected.
What is a Database-
A Database is a collection of related data organised in a way that data can be easily accessed, managed and updated. Database can be software based or hardware based, with one sole purpose, storing data.
During early computer days, data was collected and stored on tapes, which were mostly write-only, which means once data is stored on it, it can never be read again. They were slow and bulky, and soon computer scientists realised that they needed a better solution to this problem.
Larry Ellison, the co-founder of Oracle was amongst the first few, who realised the need for a software based Database Management System
What is DBMS
A DBMS is a software that allows creation, definition and manipulation of database, allowing users to store, process and analyse data easily. DBMS provides us with an interface or a tool, to perform various operations like creating database, storing data in it, updating data, creating tables in the database and a lot more.
DBMS also provides protection and security to the databases. It also maintains data consistency in case of multiple users.
Here are some examples of popular DBMS used these days:
- MySql
- Oracle
- SQL Server
- IBM DB2
- PostgreSQL
- Amazon SimpleDB (cloud based) etc.
Characteristics of Database Management System
A database management system has following characteristics:
- Data stored into Tables: Data is never directly stored into the database. Data is stored into tables, created inside the database. DBMS also allows to have relationships between tables which makes the data more meaningful and connected. You can easily understand what type of data is stored where by looking at all the tables created in a database.
- Reduced Redundancy: In the modern world hard drives are very cheap, but earlier when hard drives were too expensive, unnecessary repetition of data in database was a big problem. But DBMS follows Normalisation which divides the data in such a way that repetition is minimum.
- Data Consistency: On Live data, i.e. data that is being continuosly updated and added, maintaining the consistency of data can become a challenge. But DBMS handles it all by itself.
- Support Multiple user and Concurrent Access: DBMS allows multiple users to work on it(update, insert, delete data) at the same time and still manages to maintain the data consistency.
- Query Language: DBMS provides users with a simple Query language, using which data can be easily fetched, inserted, deleted and updated in a database.
- Security: The DBMS also takes care of the security of data, protecting the data from un-authorised access. In a typical DBMS, we can create user accounts with different access permissions, using which we can easily secure our data by restricting user access.
- DBMS supports transactions, which allows us to better handle and manage data integrity in real world applications where multi-threading is extensively used.
Advantages of DBMS
- Segregation of applicaion program.
- Minimal data duplicacy or data redundancy.
- Easy retrieval of data using the Query Language.
- Reduced development time and maintainance need.
- With Cloud Datacenters, we now have Database Management Systems capable of storing almost infinite data.
- Seamless integration into the application programming languages which makes it very easier to add a database to almost any application or website.
Disadvantages of DBMS
- It’s Complexity
- Except MySQL, which is open source, licensed DBMSs are generally costly.
- They are large in size.
History of DBMS
Here, are the important landmarks from the history:
1960 – Charles Bachman designed first DBMS system
1970 – Codd introduced IBM’S Information Management System (IMS)
1976- Peter Chen coined and defined the Entity-relationship model also know as the ER model
1980 – Relational Model becomes a widely accepted database component
1985- Object-oriented DBMS develops.
1990s- Incorporation of object-orientation in relational DBMS.
1991- Microsoft ships MS access, a personal DBMS and that displaces all other personal DBMS products.
1995: First Internet database applications
1997: XML applied to database processing. Many vendors begin to integrate XML into DBMS products.

Users: Users may be of any kind such as DB administrator, System developer, or database users.
Database application: Database application may be Departmental, Personal, organization’s and / or Internal.
DBMS: Software that allows users to create and manipulate database access,
Database: Collection of logical data as a single unit.

What is a Database Model
A database model shows the logical structure of a database, including the relationships and constraints that determine how data can be stored and accessed. Individual database models are designed based on the rules and concepts of whichever broader data model the designers adopt. Most data models can be represented by an accompanying database diagram.
Types of database models
There are many kinds of data models. Some of the most common ones include:
- Hierarchical database model
- Relational model
- Network model
- Object-oriented database model
- Entity-relationship model
- Document model
- Entity-attribute-value model
- Star schema
- The object-relational model, which combines the two that make up its name
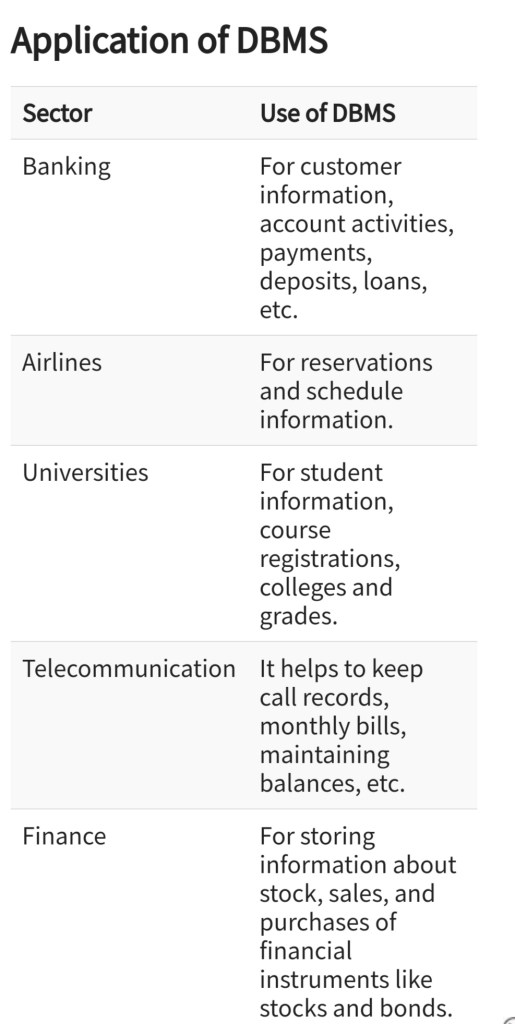
Relational model
The most common model, the relational model sorts data into tables, also known as relations, each of which consists of columns and rows. Each column lists an attribute of the entity in question, such as price, zip code, or birth date. Together, the attributes in a relation are called a domain. A particular attribute or combination of attributes is chosen as a primary key that can be referred to in other tables, when it’s called a foreign key.
Each row, also called a tuple, includes data about a specific instance of the entity in question, such as a particular employee.
The model also accounts for the types of relationships between those tables, including one-to-one, one-to-many, and many-to-many relationships. Here’s an example:
Hierarchical model
The hierarchical model organizes data into a tree-like structure, where each record has a single parent or root. Sibling records are sorted in a particular order. That order is used as the physical order for storing the database. This model is good for describing many real-world relationships.

This model was primarily used by IBM’s Information Management Systems in the 60s and 70s, but they are rarely seen today due to certain operational inefficiencies.
Network model
The network model builds on the hierarchical model by allowing many-to-many relationships between linked records, implying multiple parent records. Based on mathematical set theory, the model is constructed with sets of related records. Each set consists of one owner or parent record and one or more member or child records. A record can be a member or child in multiple sets, allowing this model to convey complex relationships.
It was most popular in the 70s after it was formally defined by the Conference on Data Systems Languages (CODASYL).

Object-oriented database model
This model defines a database as a collection of objects, or reusable software elements, with associated features and methods. There are several kinds of object-oriented databases:
A multimedia database incorporates media, such as images, that could not be stored in a relational database.
A hypertext database allows any object to link to any other object. It’s useful for organizing lots of disparate data, but it’s not ideal for numerical analysis.
The object-oriented database model is the best known post-relational database model, since it incorporates tables, but isn’t limited to tables. Such models are also known as hybrid database models.

Entity-relationship model
This model captures the relationships between real-world entities much like the network model, but it isn’t as directly tied to the physical structure of the database. Instead, it’s often used for designing a database conceptually.
Here, the people, places, and things about which data points are stored are referred to as entities, each of which has certain attributes that together make up their domain. The cardinality, or relationships between entities, are mapped as well.

A common form of the ER diagram is the star schema, in which a central fact table connects to multiple dimensional tables.
What is Data Independence
Data Independence is defined as a property of DBMS that helps you to change the Database schema at one level of a database system without requiring to change the schema at the next higher level. Data independence helps you to keep data separated from all programs that make use of it.
You can use this stored data for computing and presentation. In many systems, data independence is an essential function for components of the system.
Types of Data Independence
In DBMS there are two types of data independencenull
- Physical data independence
- Logical data independence.
Physical Data Independence
Physical data independence helps you to separate conceptual levels from the internal/physical levels. It allows you to provide a logical description of the database without the need to specify physical structures. Compared to Logical Independence, it is easy to achieve physical data independence.
With Physical independence, you can easily change the physical storage structures or devices with an effect on the conceptual schema. Any change done would be absorbed by the mapping between the conceptual and internal levels. Physical data independence is achieved by the presence of the internal level of the database and then the transformation from the conceptual level of the database to the internal level.
Examples of changes under Physical Data Independence
Due to Physical independence, any of the below change will not affect the conceptual layer.
- Using a new storage device like Hard Drive or Magnetic Tapes
- Modifying the file organization technique in the Database
- Switching to different data structures.
- Changing the access method.
- Modifying indexes.
- Changes to compression techniques or hashing algorithms.
- Change of Location of Database from say C drive to D Drive
Logical Data Independence
Logical Data Independence is the ability to change the conceptual scheme without changing
- External views
- External API or programs
Any change made will be absorbed by the mapping between external and conceptual levels.
When compared to Physical Data independence, it is challenging to achieve logical data independence.
Examples of changes under Logical Data Independence
Due to Logical independence, any of the below change will not affect the external layer.
- Add/Modify/Delete a new attribute, entity or relationship is possible without a rewrite of existing application programs
- Merging two records into one
- Breaking an existing record into two or more records
Difference between Physical and Logical Data Independence


Database Architecture
A Database Architecture is a representation of DBMS design. It helps to design, develop, implement, and maintain the database management system. A DBMS architecture allows dividing the database system into individual components that can be independently modified, changed, replaced, and altered. It also helps to understand the components of a database.
A Database stores critical information and helps access data quickly and securely. Therefore, selecting the correct Architecture of DBMS helps in easy and efficient data management.
Types of DBMS Architecture
There are mainly three types of DBMS architecture:
- One Tier Architecture (Single Tier Architecture)
- Two Tier Architecture
- Three Tier Architecture
Now, we will learn about different architecture of DBMS with diagram.null
1-Tier Architecture
1 Tier Architecture in DBMS is the simplest architecture of Database in which the client, server, and Database all reside on the same machine. A simple one tier architecture example would be anytime you install a Database in your system and access it to practice SQL queries. But such architecture is rarely used in production.
2-Tier Architecture

A 2 Tier Architecture in DBMS is a Database architecture where the presentation layer runs on a client (PC, Mobile, Tablet, etc.), and data is stored on a server called the second tier. Two tier architecture provides added security to the DBMS as it is not exposed to the end-user directly. It also provides direct and faster communication.
In the above 2 Tier client-server architecture of database management system, we can see that one server is connected with clients 1, 2, and 3.
Two Tier Architecture Example:
A Contact Management System created using MS- Access.
3-Tier Architecture
A 3 Tier Architecture in DBMS is the most popular client server architecture in DBMS in which the development and maintenance of functional processes, logic, data access, data storage, and user interface is done independently as separate modules. Three Tier architecture contains a presentation layer, an application layer, and a database server.
3-Tier database Architecture design is an extension of the 2-tier client-server architecture. A 3-tier architecture has the following layers:null
- Presentation layer (your PC, Tablet, Mobile, etc.)
- Application layer (server)
- Database Server

The Application layer resides between the user and the DBMS, which is responsible for communicating the user’s request to the DBMS system and send the response from the DBMS to the user. The application layer(business logic layer) also processes functional logic, constraint, and rules before passing data to the user or down to the DBMS.
Three schema Architecture
- The three schema architecture is also called ANSI/SPARC architecture or three-level architecture.
- This framework is used to describe the structure of a specific database system.
- The three schema architecture is also used to separate the user applications and physical database.
- The three schema architecture contains three-levels. It breaks the database down into three different categories.
The three-schema architecture is as follows:
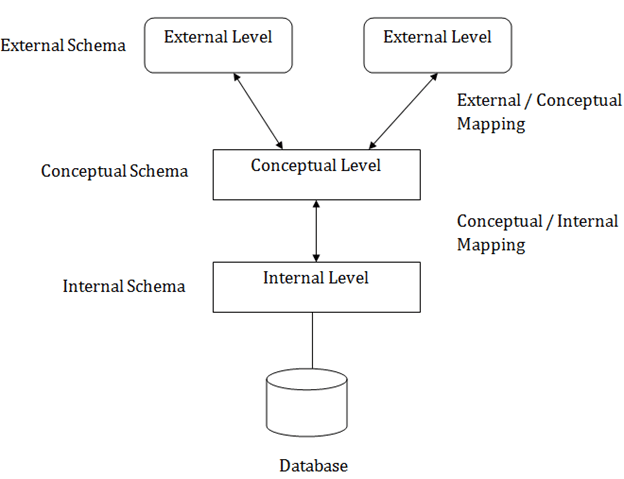
In the above diagram:
- It shows the DBMS architecture.
- Mapping is used to transform the request and response between various database levels of architecture.
- Mapping is not good for small DBMS because it takes more time.
- In External / Conceptual mapping, it is necessary to transform the request from external level to conceptual schema.
- In Conceptual / Internal mapping, DBMS transform the request from the conceptual to internal level.
1. Internal Level
- The internal level has an internal schema which describes the physical storage structure of the database.
- The internal schema is also known as a physical schema.
- It uses the physical data model. It is used to define that how the data will be stored in a block.
- The physical level is used to describe complex low-level data structures in detail.
2. Conceptual Level
- The conceptual schema describes the design of a database at the conceptual level. Conceptual level is also known as logical level.
- The conceptual schema describes the structure of the whole database.
- The conceptual level describes what data are to be stored in the database and also describes what relationship exists among those data.
- In the conceptual level, internal details such as an implementation of the data structure are hidden.
- Programmers and database administrators work at this level.
3. External Level
- At the external level, a database contains several schemas that sometimes called as subschema. The subschema is used to describe the different view of the database.
- An external schema is also known as view schema.
- Each view schema describes the database part that a particular user group is interested and hides the remaining database from that user group.
- The view schema describes the end user interaction with database systems.
